Think, Verbalize, then Speak:
Bridging Complex Thoughts and Comprehensible Speech
Abstract
Spoken dialogue systems increasingly employ large language models (LLMs) to leverage their advanced reasoning capabilities. However, direct application of LLMs in spoken communication often yield suboptimal results due to mismatches between optimal textual and verbal delivery. While existing approaches adapt LLMs to produce speech-friendly outputs, their impact on reasoning performance remains underexplored. In this work, we propose Think-Verbalize-Speak a framework that decouples reasoning from spoken delivery to preserve the full reasoning capacity of LLMs. Central to our method is verbalizing, an intermediate step that translates thoughts into natural, speech-ready text. We also introduce ReVerT, a latency-efficient verbalizer based on incremental and asynchronous summarization. Experiments across multiple benchmarks show that our method enhances speech naturalness and conciseness with minimal impact on reasoning.
Trade-off between Reasoning capability and Speech-friendliness
Traditional dialogue systems face a fundamental trade-off between reasoning capability and speech-friendliness. While complex reasoning requires structured intermediate steps and detailed explanations, spoken delivery demands concise and natural expressions that are easy to follow when heard aloud.
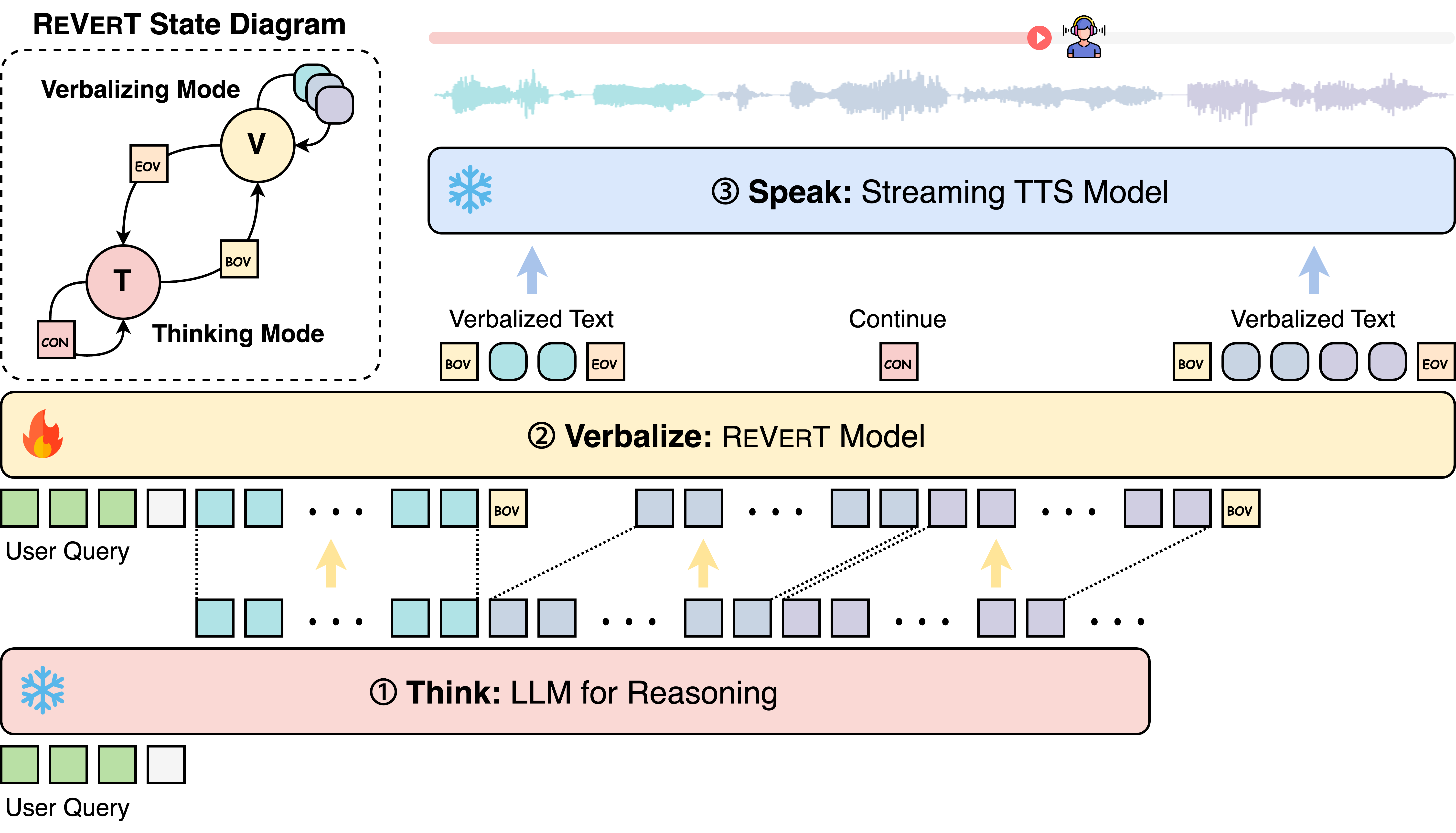
Think-Verbalize-Speak and ReVerT
The Think-Verbalize-Speak (TVS) framework addresses this challenge by separating reasoning from speech delivery. In the Think stage, LLMs leverage their full reasoning capabilities to solve complex problems. The Verbalize stage then transforms these reasoning outputs into natural, speech-appropriate expressions. Finally, the Speak stage generates the final audio through text-to-speech synthesis.
We introduce ReVerT, a novel verbalizer that efficiently handles the Verbalize stage through incremental and asynchronous summarization. ReVerT minimizes latency while maintaining the quality of speech-friendly transformations, making real-time spoken dialogue systems more practical and responsive.
Data Construction Pipeline
Our data construction pipeline efficiently creates large-scale Think-Verbalize datasets through three key steps: Solve, Summarize, and Scatter. First, we solve reasoning problems using existing datasets to extract comprehensive "Think" data through chain-of-thought reasoning. Then, we summarize these detailed reasoning traces into natural, speech-friendly "Verbalize" expressions. Finally, we scatter the speech-friendly summaries across the reasoning process, placing each summary immediately after its associated reasoning step and marking them with special tokens for training data preparation.

Samples
Explore real samples across various reasoning tasks (GSM8K, SciBench, 2WikiMultiHopQA) to compare different methodologies. You can examine both the generated text and audio for each approach to directly observe the effectiveness of the TVS framework.
| Question | Loading question and answer... | ||||